The Most Comprehensive Publicly Available Query Fan-Out Data You Can Extract From ChatGPT
When ChatGPT answers a question using web search, it generates multiple search queries from your prompt (the "fan-out"), retrieves a pool of results, and cites a small subset of them in the final answer. The ChatGPT interface shows you the citations. It does not show you the fan-out queries, the full retrieval pool, or which retrieved results were passed over.
That data exists, and it is more complete than anything available from third-party AI-visibility tools, which work by inference, re-running prompts at scale and observing outputs. This is the actual record of a real conversation: every query the model generated, all 90 results it retrieved, and the 18 it cited.
I built a userscript that extracts it from any ChatGPT conversation in your own account and produces a CSV (33 columns per result) plus a formatted report. This post documents what the data contains, findings from a real audit, and how it works.
Want access to this tool? It's not publicly listed - but I am sharing the GitHub repository freely to people who reach out. Schedule a call, message me on LinkedIn, or email [email protected] and I'll get you set up.
Prefer video? Here is a full walkthrough:
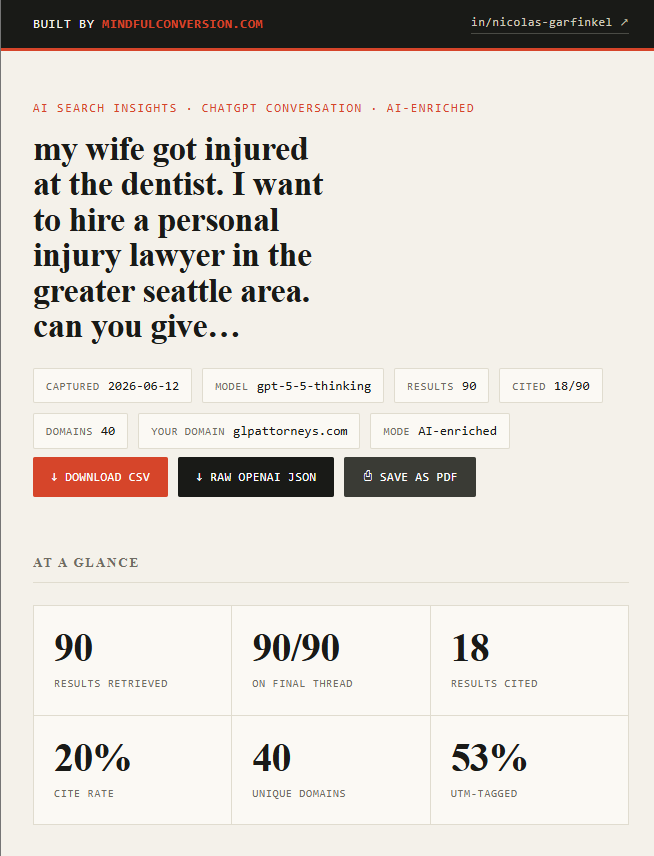
The test case
Prompt: "my wife got injured at the dentist. I want to hire a personal injury lawyer in the greater seattle area. can you give…", a high-intent, in-market consumer query. Focus domain for the audit: an established Seattle personal injury firm.
What the export captured:
| Metric | Value |
|---|---|
| Fan-out queries generated | 6 |
| Results retrieved | 90 |
| Unique domains retrieved | 40 |
| Results cited | 18 (20% cite rate) |
URLs carrying utm_source=chatgpt |
53% |
| Focus domain retrievals | 0 |
The structural point this data makes concrete: AI visibility has two gates. A page must first be retrieved (pulled into the model's working set), then cited (used in the answer). "Did ChatGPT mention us" collapses both into one question; the diagnosis and remediation differ depending on which gate fails. This dataset lets you measure each gate separately.
Finding 1: Zero retrievals for an established local firm
The script prompts for a focus domain before export and builds a dedicated section showing every retrieval and citation for that domain.
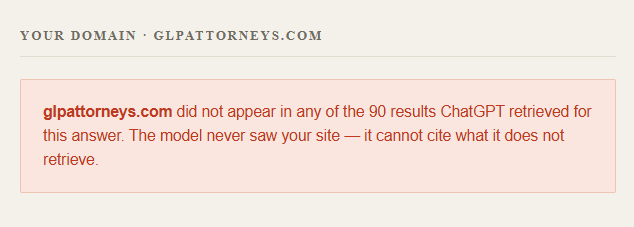
Result: the firm appeared in 0 of 90 retrieved results for a directly relevant query in its own metro. This is a retrieval-gate failure, not a citation-gate failure, the model never saw the site, so no amount of on-page optimization for citation would have mattered. Google rankings did not predict this outcome; ChatGPT's retrieval is a different system with different winners, and this is measurable per query.
For agency work, this is the most direct evidence you can put in front of a prospect: a count, not an interpretation.
Finding 2: The model embedded brand names in its own search queries
The six fan-out queries the model generated:

Five are predictable reformulations: Seattle dental malpractice lawyer variants, a Washington State Bar lookup, a statute-of-limitations query. The sixth:
"Washington dental malpractice attorney Seattle Scott Hughes SGB medical malpractice Colburn Law"
The model named specific attorneys and firms in the query itself. It did not discover Schroeter Goldmark & Bender, Scott Hughes, or Colburn Law via search; it searched to verify and source entities it already held from training data. All three were cited in the final answer.
Implication: a portion of AI search visibility is possibly determined before retrieval happens, by whether the brand exists in the model's prior knowledge strongly enough to be queried by name. That is a function of earned media, reviews, and sustained entity presence.
Secondary use: fan-out queries are model-generated keyword expansion. One of the six here (the RCW statute query) identifies a content category covered below.
Finding 3: Directories were retrieved repeatedly and cited zero times
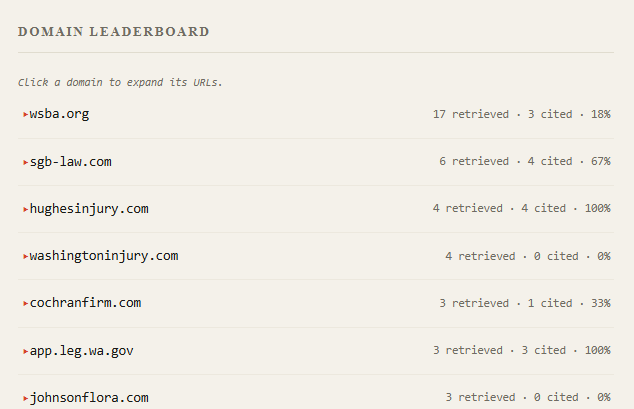
Citation performance by domain type in this conversation:
| Domain | Retrieved | Cited | Cite rate |
|---|---|---|---|
| wsba.org (state bar) | 17 | 3 | 18% |
| lawinfo.com, lawyers.com, martindale.com, justia.com, legalmatch.com (directories, combined) | 10 | 0 | 0% |
| sgb-law.com (firm site) | 6 | 4 | 67% |
| hughesinjury.com (solo attorney site) | 4 | 4 | 100% |
| app.leg.wa.gov (statute text) | 3 | 3 | 100% |
Legal directories rank on page one of Google for these queries and have for years. ChatGPT retrieved them and cited none. The pattern is consistent with how answer composition works: a directory listing page ("Compare 16 local law firms") contains nothing quotable: no named entity, no specific claim, no fact. A firm's own page stating who they are, what they handle, and where, supplies citable material directly.
If you're struggling to get cited, this pattern is worth a close look. More research is needed on whether directory listings affect the citation rates of your own site, but across the conversations I've pulled, I often don't see many directory sites being cited, even though they routinely show up in the result set. Directories may still matter for entity reinforcement (Finding 2), but in this data they are not converting to citations.
Finding 4: Exact-intent title phrases cited at 5× the baseline
The export runs an n-gram analysis: bi/tri-grams from result titles and snippets, split by cited vs. uncited results, with a cite-lift multiplier against the conversation's overall 20% cite rate.

| Title phrase | Cited | Uncited | Lift |
|---|---|---|---|
| dental malpractice attorney | 2 | 0 | 5.0× |
| attorney bellevue wa | 4 | 0 | 5.0× |
| seattle medical malpractice | 5 | 6 | 2.3× |
| medical malpractice | 8 | 24 | 1.3× |
| personal injury | 3 | 8 | 1.4× |
Note the vocabulary shift: the user wrote "personal injury lawyer"; the model reformulated to dental malpractice and medical malpractice. Titles matching the reformulated vocabulary cited at 100%; titles using the user's original vocabulary ("personal injury") barely exceeded baseline. The 4-for-4 domain in Finding 3 has "Medical Malpractice & Dental Malpractice Attorney | Bellevue, WA" in its title tag.
Practical reading: optimize titles against the model's reformulated queries (which the fan-out data gives you), not only against the user-facing keyword.
Caveat, which the tool itself displays: this is one conversation, n-grams measure lexical correlation in a small sample, and repeated citations of a single page inflate its phrases. Treat as hypothesis generation for testing, not as established weighting.
Finding 5: Statutory content cited at 100%
app.leg.wa.gov (raw text of RCW 4.16.350 and Chapter 7.70) went 3-for-3 on citations. Firm-authored statute-of-limitations explainers were also retrieved and cited. One entire fan-out query was devoted to the statute of limitations, for a prompt that never asked about deadlines.
The model was assembling a complete answer: candidate firms, a referral path through the bar association, and the filing deadline. Content that explains the governing statute is a citation surface in its own right; the firm that owns the clearest version of "how long do I have to file a dental malpractice claim in Washington" gets cited as an authority alongside whatever firms get listed.
What the export contains
Per conversation, one click produces:
- Summary stats, retrievals, citations, cite rate, unique domains, active-branch vs. regenerated results, and share of URLs carrying
utm_source=chatgpt(53% here; this parameter is segmentable in GA4) - Focus-domain section, retrieval/citation counts, share of retrievals, and the exact snippets ChatGPT extracted from your pages (these snippets are the literal text the model works with; weak snippets generally trace to weak page intros and meta descriptions), or a zero-visibility callout
- URL source breakdown, owned sites vs. review aggregators vs. directories vs. Maps/YouTube/Reddit, each with its own cite rate
- N-gram analysis, phrases over-indexing in cited results, from titles and from snippets, with cite lift
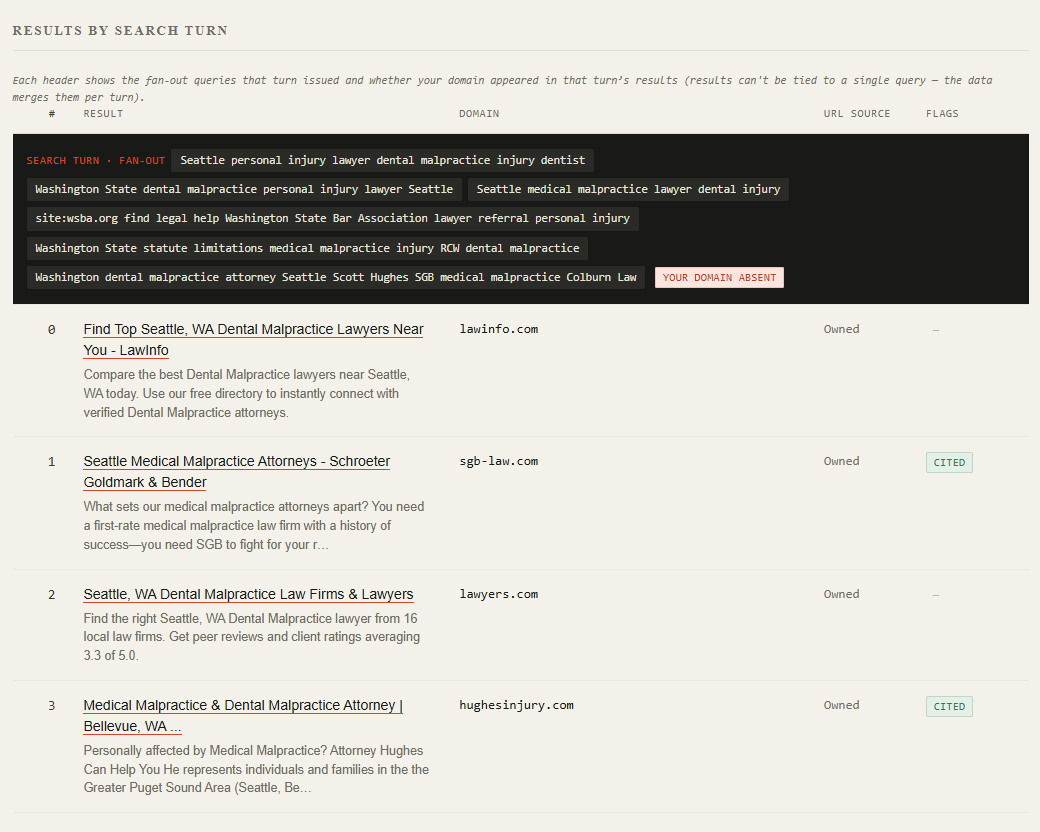
- Query fan-out, every search query the model generated
- Domain leaderboard, all domains by retrieval count, expandable to individual URLs with citation flags
- Full results table, all rows grouped by search turn, with each turn's queries and per-result cited/utm/focus-domain flags
Plus the CSV (33 columns per result), an optional AI-enrichment pass that extracts entity names, star ratings, review counts, and price signals from snippets, and a Save-as-PDF button for client deliverables.
How it works
The tool is a userscript. It runs entirely in your own browser, on conversations in your own ChatGPT account. No data is sent to me or any third party.
- Install Tampermonkey (Chrome, Edge, Firefox, Safari) or Violentmonkey.
- Tampermonkey icon → Create a new script → paste the script → save.
- Open any ChatGPT conversation that used web search. A floating "↓ AI Search export" button appears bottom-right.
- Click it. First run prompts for your focus domain (changeable later via the Tampermonkey menu). CSV downloads; report opens in a new tab; ⎙ Save as PDF for the client version.
Optional enrichment: Tampermonkey menu → 🔑 Set OpenAI key. The key is stored locally and sent only to api.openai.com; a typical conversation costs pennies. Use a spend-capped key.
Suggested workflow
- Define 5–10 high-intent prompts a real buyer in the category would type, conversational phrasing, not keyword-speak ("my wife got injured at the dentist," not "dental malpractice lawyer Seattle").
- Run each fresh and export. Note which prompts trigger web search at all.
- Read the focus-domain section first; a retrieval count of zero reframes the entire engagement.
- Mine fan-out queries for the model's vocabulary and for content gaps (e.g., the statute query).
- Compare the domain leaderboard against Google rankings; the citation winners are frequently different.
- Use the n-gram tables to rewrite title tags and page intros against the model's reformulated vocabulary, then re-run the prompt set later and diff the CSVs.
Limitations
- Results are grouped by search turn, not individual query; each turn's results are merged in the underlying data, so per-query attribution is not possible. Any tool claiming query-level result mapping for ChatGPT is inferring it.
- "Cited" is a proxy for "used." There is no separate read/consult signal in the data.
- One conversation is a snapshot. Results vary by session, location, and model routing; run repeated exports before drawing conclusions.
- N-gram output is lexical correlation, not causal weighting.
Get access to the tool
If you're interested in getting access to this tool, or in having this audit run across your category's buyer prompts, reach out. Schedule a call, connect on LinkedIn, or email [email protected].

Written by
Nicolas GarfinkelFounder & CEO
Nicolas is the founder of Mindful Conversion, specializing in analytics and growth.